'Cattle, not pets' for code
In the 2010s, cloud computing enabled a new way of managing servers famously characterized as ‘cattle, not pets’. The ability to cheaply and efficiently provision and release compute resources created a paradigm shift: servers which were once discrete, expensive, and carefully-managed physical resources became disposable, interchangeable abstractions managed at arms-length.
In 2025, LLMs seem poised to deliver a similar revolution for code. Many software engineering practices are downstream of the assumption that code is expensive to create and manage. As the cost of code generation craters, powerful and efficient new ways of working are suddenly possible. What tools, systems, and practices will be necessary to enable the ‘cattle, not pets’ paradigm for code? And what practical roadblocks exist to building software in this way?
Cattle, not pets
In his history of the ‘cattle, not pets’ analogy (which I recommend), Randy Bias explains the concept applied to cloud computing:
In the old way of doing things, we treat our servers like pets, for example Bob the mail server. If Bob goes down, it’s all hands on deck. The CEO can’t get his email and it’s the end of the world. In the new way, servers are numbered, like cattle in a herd. For example, www001 to www100. When one server goes down, it’s taken out back, shot, and replaced on the line.
Randy emphasises the disposability of servers as the foundation of the analogy; cloud computing obviates the need for close, manual attention (“hand-feeding”) and enables more automated and scalable ways of managing compute resources.
Servers were expensive, and therefore few, and therefore precious (‘pets’). When they became cheap, there was no reason to hold onto this preciousness and much to be gained by relinquishing it.
It seems to me that code today is in a similar position: it is treated preciously because (historically) it has been expensive to create. Now that there has been a step change in the cost, it is not at all clear to me that the preciousness is still warranted. If anything, we simply lack the equipment and facilities for ‘industrial farming’ software engineering.
With apologies to Randy, I’d like to (ab)use his analogy as a framework for exploring the tools and practices we will need to invent to transition to a code-as-cattle way of working.
Code as pets
It is hard to think of a pithier characterization of code in modern software engineering than ‘pets’. Code is crafted by hand, reviewed, and iterated on until it satisfies not just the product requirements but also our automated tests, style guides, and aesthetic eye. The process invariably builds emotional attachment between author and text, as anyone who has stridently defended their PR from myopic review comments can attest.
Codebases are carefully groomed and pampered to keep them beautiful. Much time and thought is spent on their various modules and interfaces, with this attention to detail expensed as the vanguard of future productivity. While the cost of maintenance is high, many have seen the consequences of the alternative: codebases shamefully neglected by their owners until they are unkempt, unsociable, and nigh-impossible to live with.
Emotional attachment is also felt at the end, when a product has been sunset and the time has come for a single, somber PR which blanketly deletes all eighty thousand lines. The team knows it is the right thing to do, but it still hurts to see that beautiful code vanish into the beyond.
Code as cattle
What would it look like to treat code as cattle? Here we must begin to speculate, but I have some ideas. Generically we can think of ‘healthy’ code as code that satisfies a set of three constraints: intent, testing, and style.
The primary constraint is the author’s intent: the code must fulfill the purpose that the author wishes. LLMs provide us the novel ability to specify this intent in English and generate, in a limited but expanding set of circumstances, the corresponding code. Of course, the problem of ‘precisely specifying intent’ is not to be taken lightly. Many smart people have tried over decades to devise such systems with limited success; no solutions more abstract than popular high-level programming languages have yet seen widespread adoption. Still, clearly we have a powerful new tool in the intent-to-code toolbox.
The second constraint is automated testing. For large software systems that must be evolved over time, testing has proven out its value. While tests are ‘downstream’ of intent (and therefore LLM-based generation), it seems likely that they will continue to play a critical and separate role. Once written, tests become a highly efficient mechanism for verifying that new modifications (which fulfill some new intent) do not violate previous intents which should be unaffected by the change.
Context management has emerged as a key concern when applying LLMs to software systems at scale. Tests can be thought of as a robust ‘context-preserving’ measure; they automate what would otherwise be a context-intensive verification of previous intents on each change. This justifies their presence as a standalone constraint, despite (likely) being a product of the intents themselves.
The third constraint is the set of cross-cutting design choices that determine what is idiomatic for a given project. Typically these choices manifest as style guides, policies (such as what tools, systems, and packages are allowed or disallowed), and conventions for solving certain subproblems (e.g. ‘use module foo for exponential backoff’). All are unified in their ultimate goal: to drive consistency in the code and overall system design.
Together, these three concerns form a framework for identifying ‘healthy’ or valid code.
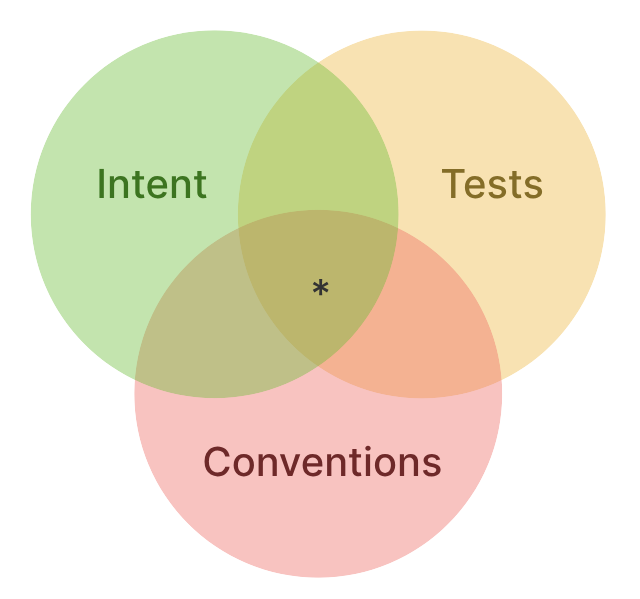
This prompts a key question: is any code that satisfies these three criteria equally valid?
I believe the answer must be yes, and that this is the defining aspect of the code-as cattle paradigm; to operate in this way we must cease to care about the minutiae of the code itself and care only for the framework that creates it. If the output of the system is not satisfactory then we adjust the constraints and regenerate, since the code itself is disposable.
Building a code ranch
The pieces of this three-pronged system are available in various forms today. All the popular coding models can accept intent (typically in chat format) and verify generated code against tests (if instructed in some way). Most models also provide a utility for defining cross-cutting style and conventional guidance in the form of a durable instructions file (e.g. AGENTS.md) that is automatically added to the context window.
Possibly the biggest missing piece is a durable representation of the ‘intent’ of the system. Most current tools treat chats as ephemeral with code output as the only artifact of generation. This has sufficed for plugging LLMs into existing development practices where they are used to accelerate the existing workflow of an individual engineer.
However, it is difficult to extend the ‘chat’ paradigm beyond this limited use as an accelerant. Daniel Delaney has an excellent critique of the pattern:
Current AI tools pretend writing software is like having a conversation. It’s not. It’s like writing laws. You’re using English, but you’re defining terms, establishing rules, and managing complex interactions between everything you’ve said.
Try writing a tax code in chat messages. You can’t. Even simple tax codes are too complex to keep in your head. That’s why we use documents—they let us organize complexity, reference specific points, and track changes systematically. Chat reduces you to memory and hope.
To transform rather than augment existing workflows, it will be necessary for the intent to become a durable part of the system (i.e. checked into source control). Instead of a chat which begins as a blank slate (modulo the instructions file), the input to the LLM will be a diff of the existing intent which lives alongside the code itself.
The organization of these intent files and their contents is a significant problem, on par with the challenge of organizing the code itself. But like code organization, it seems reasonable to expect that with experimentation multiple empirically-valid options will emerge.
The two other pillars, tests and conventions, are both well-supported today. Most models can verify their generated code against existing tests (though some oversight is necessary to ensure they are not simply deleting failing test cases) and various instruction files provide a control (albeit, a simple one) for convention-related guidance.
For both, the primary challenge in systematizing them is LLM context management. As chats lengthen, either with continued back-and-forth or other content like test results, earlier content is pushed out of the context window causing performance to decline markedly.
The best immediate solution to this problem seems to be ‘subagents’, which expose the LLM as a tool to itself. Specific, repeated tasks such as ‘run the test suite and report the results’ or ‘review this code for style violations’ can be executed in a separate context window, preserving the context of the ‘main’ agent. It seems that the ability of multi-agent systems to operate at different levels of abstraction will be key to highly-automated development practices.
Purpose-built tooling for managing a roster of agents seems like a logical next step in advancing this way of working. While today’s tooling allows agent configurations to be managed with source control, there are no widely-adopted solutions for agent observability. Familiar concepts like session replay and A/B testing can be applied within a single UI to empower engineers to monitor, evaluate, and evolve their agent systems.
At a higher level, some form of project-management tooling will also be needed to aid in the ‘farming out’ of tasks to agent subsystems.
Practical concern: specifying intent
History indicates that English is not a suitably precise language for specifying software behavior. Can a collection of ‘spec’ files, distributed across a codebase, realistically serve as the authoritative ‘source’ for a system’s behavior? There are two reasons I think it may be possible.
First, criticism (or cautionary tales) about the fallibility of English software specifications typically centers on waterfall development models where the specification writing happens entirely up front. The weakness of this model is that gaps and contradictions in the spec are difficult to avoid and costly to resolve when they are later discovered during implementation. In contrast, a distributed system of ‘intent’ files would operate in a much more agile-esque way: the content can be freely iterated on and gaps, which naturally occur, can be easily closed. Rather than being expensive to resolve, the cost of this iteration trends down with the cost of generating code.
Second, LLMs are simply an incredibly powerful tool for semantic tasks. Evaluating English specs for internal computational completeness and external consistency is a tedious task, one where human accuracy drops as the task scales. It seems plausible that today’s models can already produce a level of spec correctness-checking that was previously unachievable. If this problem still remains intractable at scale, we should at least see how much further it can take us.
Implications
Some existing software development practices seem to naturally support a ‘code as cattle’ way of working. Source control provides a universal interface for LLMs to take action; as a result it makes increasing sense to adopt configuration-as-code for all systems. Conversely, systems that can be managed in this way become more attractive (and this extends to many domains beyond production).
Along with this, the need for code review (or some evolved level of review) is deepened. Like agent-based project management, this is an area where the dominant tooling of the next decade may not yet have been built.
Automated testing, as ever, remains an invaluable tool for building software at scale and over time. The ability for tests to serve as a context-preserving evaluation against previous intents makes them even more valuable.
Do I hate this?
I don’t like the idea of relinquishing my direct connection to the code I create. Feasibility aside, I am one of those people that enjoys the manual crafting of code as an end unto itself. That enjoyment is part of how I ended up in this business to begin with and I wonder whether pragmatism will soon require me to let it go, at least professionally.
When I signed up to be a software engineer, I was under the impression there would always be pets involved. Or at most, a modest herd of cattle where I could know all their names.
Still, I don’t think there’s a contradiction in loving the craft of code but treating it disposably. I can still go home to my pets at night.